
Какмыспаслипродуктпоследвухкомандиза1,5месяцаподготовилиегокключевомумероприятию
Заказчик — онлайн-платформа-агрегатор, на которой представлены инвестиционные проекты, консалтинговые услуги, компании из сфер торговли драгоценными металлами и недвижимости. Один из ключевых активов платформы — продуктовый реестр, агрегирующий данные из множества внешних источников.
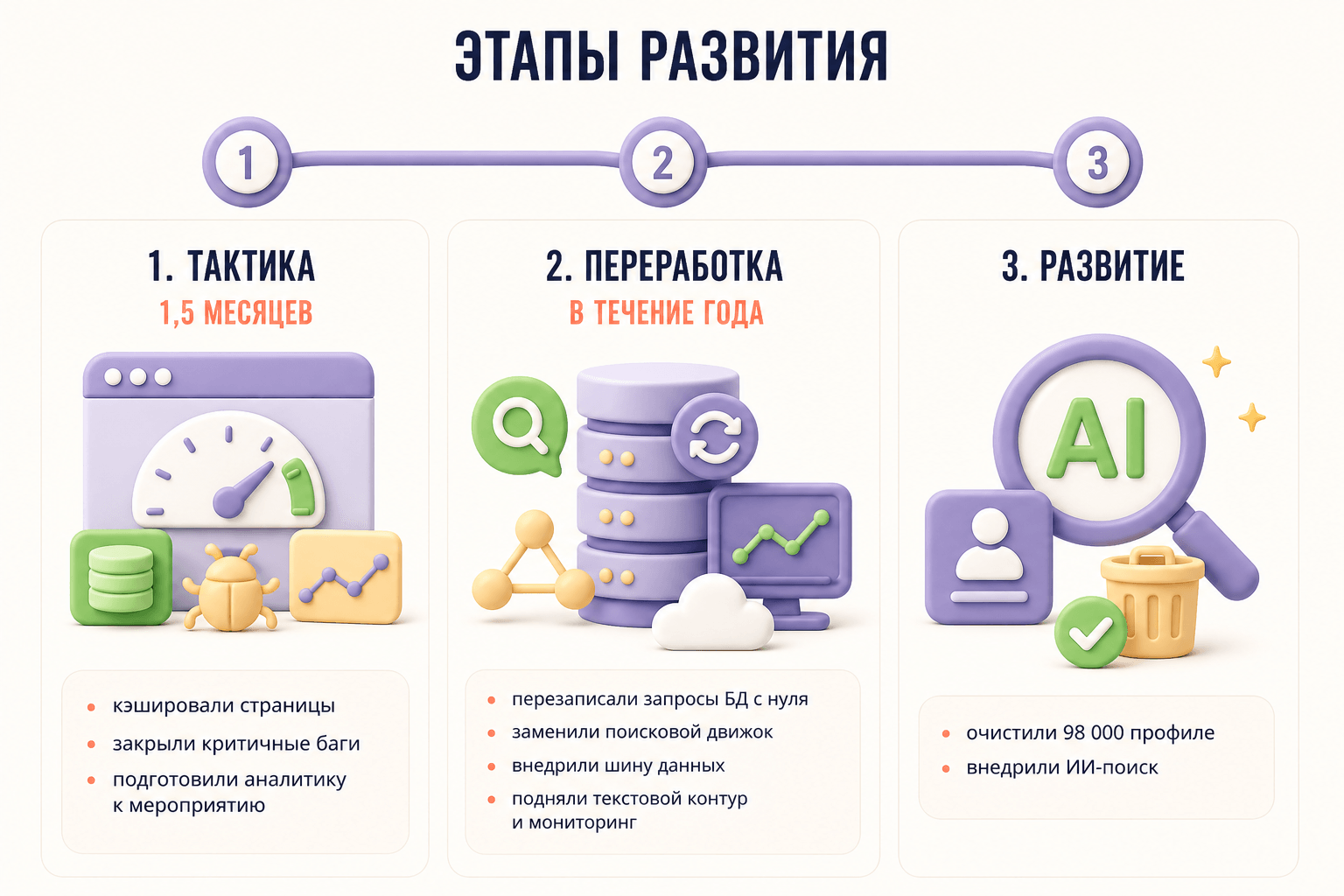
Задача — принять на поддержку и развитие проблемный проект реестра, доставшийся заказчику после двух некомпетентных команд. Требовалось доработать несданный функционал, кардинально ускорить работу и подготовить продукт к ключевому ежегодному отраслевому мероприятию за полтора месяца.
Проблема — проект перешел к нам в критическом состоянии. «Под фундамент» были заложены неверные архитектурные решения: все роуты построены по единому «сверхжадному» шаблону, который тянул из базы все связанные данные без разбора. Страницы реестра грузились по 20–60 секунд. Отсутствовал тестовый контур, мониторинг ошибок и логирование. Деплой производился вручную. Взаимодействие с ключевыми внешними системами работало с критическими сбоями: данные не доходили полностью, заявки терялись. Предыдущая команда утратила контроль над проектом, а документация по архитектуре отсутствовала полностью.
Организационная специфика: продукт работает в сегменте B2B с высокими регуляторными требованиями. Заказчик установил жёсткую двухнедельную отчётность с сдачей по строгим шаблонам. Каждый спринт включал протокол испытаний с тест-кейсами и детальный отчёт со скриншотами каждого изменения в коде. Задачи требовали предварительной оценки, зачастую «вслепую», и согласования на уровне высшего руководства.
Решение — мы провели полный ресерч параллельно с разработкой, внедрили кэширование как быстрое «тактическое» решение, а затем переписали все критические запросы к БД с нуля. За месяц до мероприятия создали новую аналитику. В долгосрочной перспективе — внедрили многослойную архитектуру (сервис-репозиторий), шину данных для внешних интеграций, заменили поисковый движок и наладили все цепочки обмена с внешними системами.
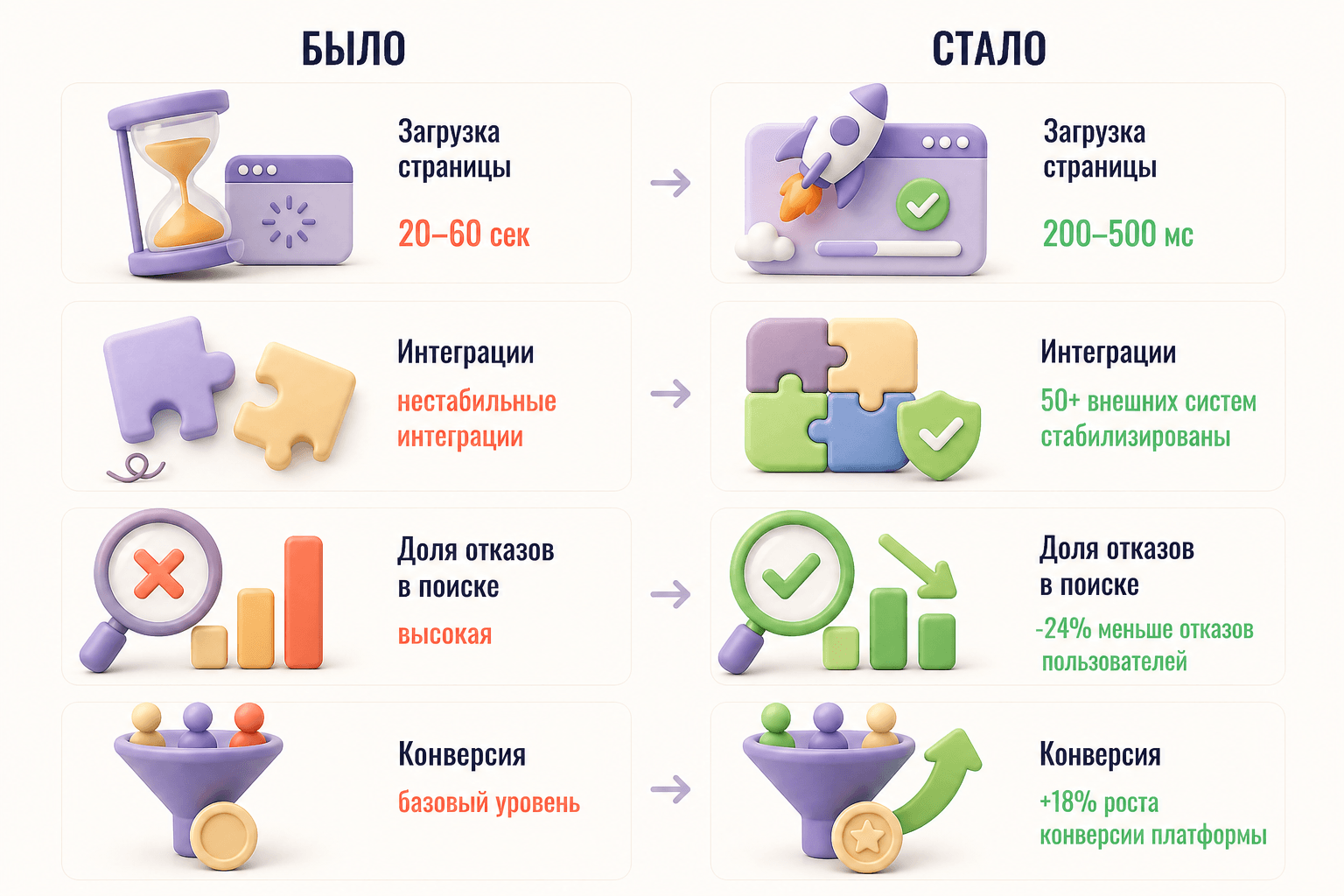
Результат — время загрузки страниц сократилось с десятков секунд до 200–500 миллисекунд. Продукт стабильно прошёл ключевое мероприятие. За два года мы превратились из «пожарной команды» в доверенного долгосрочного партнёра, с которым заказчик продолжает работать. Вся отчётность теперь формируется по утверждённым шаблонам без переделок.
Подробнее о ходе работ и технических деталях — ниже.
ИзнеподдерживаемогоLegacy—встабильныйпродуктсострогойприёмкой
Заказчик пришёл к нам с проектом реестра, который предыдущие подрядчики уже дважды пытались реанимировать, но безуспешно. Наша задача была не в разработке с нуля, а в спасении действующего продукта с огромной базой данных.
На старте ситуация казалась типичной для legacy: есть сайт, есть код, есть даже предыдущая команда. Но реальность оказалась хуже. Ключевой сотрудник предыдущей команды то «болел», то «ничего не знал». Нам не передали ни знаний об архитектуре, ни логики принятых решений. Документация отсутствовала как класс. Единственное, что мы получили — медленный, нестабильный код и критику со стороны заказчика в адрес предыдущих разработчиков.
При этом продукт должен был не просто работать — через полтора месяца ему предстояла презентация на ключевом отраслевом мероприятии. А мы ещё даже не понимали до конца масштаб проблем.
Это означало, что мы не можем позволить себе классический подход с долгим ресёрчем. Нужно было одновременно изучать чужой запутанный код, чинить критичные баги и создавать новый функционал к дедлайну.
Этап1.Ресёрч«налету»,«костыли»ибоевоекрещениенапроектно-образовательноминтенсиве
Мы не начали писать код сразу. Сначала нужно было понять, где корень проблемы и можно ли с этим вообще работать.
Первые две недели ушли на полный ресёрч. Картина оказалась следующей:
«Сверхжадные» запросы и неработающий поиск. Первая команда построила все роуты по единому универсальному шаблону на собственном самописном фреймворке. Работало это так: чтобы показать карточку компании, запрос тянул вообще всё — всю команду, их пользовательские аккаунты, историю сделок, связанные контракты и прочее. Это создавало гигантский объём нерелевантных данных. Внешний поисковый движок Elasticsearch был настроен неоптимально и использовался «к месту и не к месту», добавляя к загрузке ещё 5+ секунд. Как итог — ключевые страницы с большими данными грузились по 20–60 секунд.
Хаос в интеграциях. Обмен данными с критически важными внешними системами был реализован фрагментарно. Часть данных не передавалась вообще, из-за чего заказчику приходилось в конце периода вручную дозаполнять таблицы. Фоновые задачи не выполняли свои функции: например, отправка экспертных заключений просто не работала. Отсутствовали таймауты и обработчики ошибок при запросах во внешние API — любой сбой формата данных «вешал» задачу без каких-либо уведомлений.
Инфраструктурный вакуум. Отсутствовал тестовый контур. Деплой на все среды, кроме одной, производился вручную. Не было Sentry или любого другого мониторинга ошибок. Grafana, внедрённая в проект, использовалась не для мониторинга, а для отрисовки 6 некрасивых графиков в разделе аналитики. Линтеры и чекеры кода не применялись вовсе.
Параллельный трек — подготовка к проектно-образовательному интенсиву. Одновременно с разбором завалов нам поставили задачу: за полтора месяца создать новую аналитику для презентации на ключевом мероприятии. Старая «аналитика» была теми самыми 6 графиками Grafana, которые не годились для презентации.
Это был кризисный момент. Мы не могли ни отказаться от мероприятия, ни отложить стабилизацию.
Мы действовали по двум направлениям:
- «Костылили» критичные места. Внедрили кэширование страниц, чтобы снизить нагрузку и «заморозить» проблему медленной загрузки до лучших времён. Это не решало проблему архитектурно, но дало пользователям приемлемый опыт.
- Форсировали новый функционал. Разработали и презентовали новую аналитическую панель на интенсиве, несмотря на сжатые сроки и нестабильную основу. В этот период команда работала овертайм, но это была краткая и разовая история — не системная практика.
Как организовали параллельный ресёрч и разработку — смотрите в нашей статье, где мы детально разобрали первую, самую кризисную фазу проекта.
Проект выжил и успешно прошёл мероприятие, но мы понимали: это была лишь отсрочка. Фундаментальные проблемы требовали системного лечения.
Этап2.Системноелечение:от«костылей»кновойархитектуре
После острой фазы мы приступили к плановому «ремонту», который занял около года.
Переписывание роутов с нуля (v2). Править «сверхжадные» запросы в старой ORM было бессмысленно — слишком глубоко зашита логика связей в их самописном фреймворке. Мы приняли решение переписать все критические запросы в новую версию API (v2) с использованием паттерна «сервис-репозиторий». Каждый роут теперь запрашивал только те данные, которые реально нужны фронту. Это дало ошеломляющий эффект: время загрузки сократилось с 20–60 секунд до 200–500 миллисекунд, то есть в 50 и более раз.
Замена поискового движка. Мы отказались от использования Elasticsearch для пользовательского поиска. Вместо него внедрили полнотекстовый поиск на базе самого PostgreSQL, что убрало 5-секундную задержку и упростило архитектуру. Elasticsearch оставили только для админки, где его использование было оправдано.
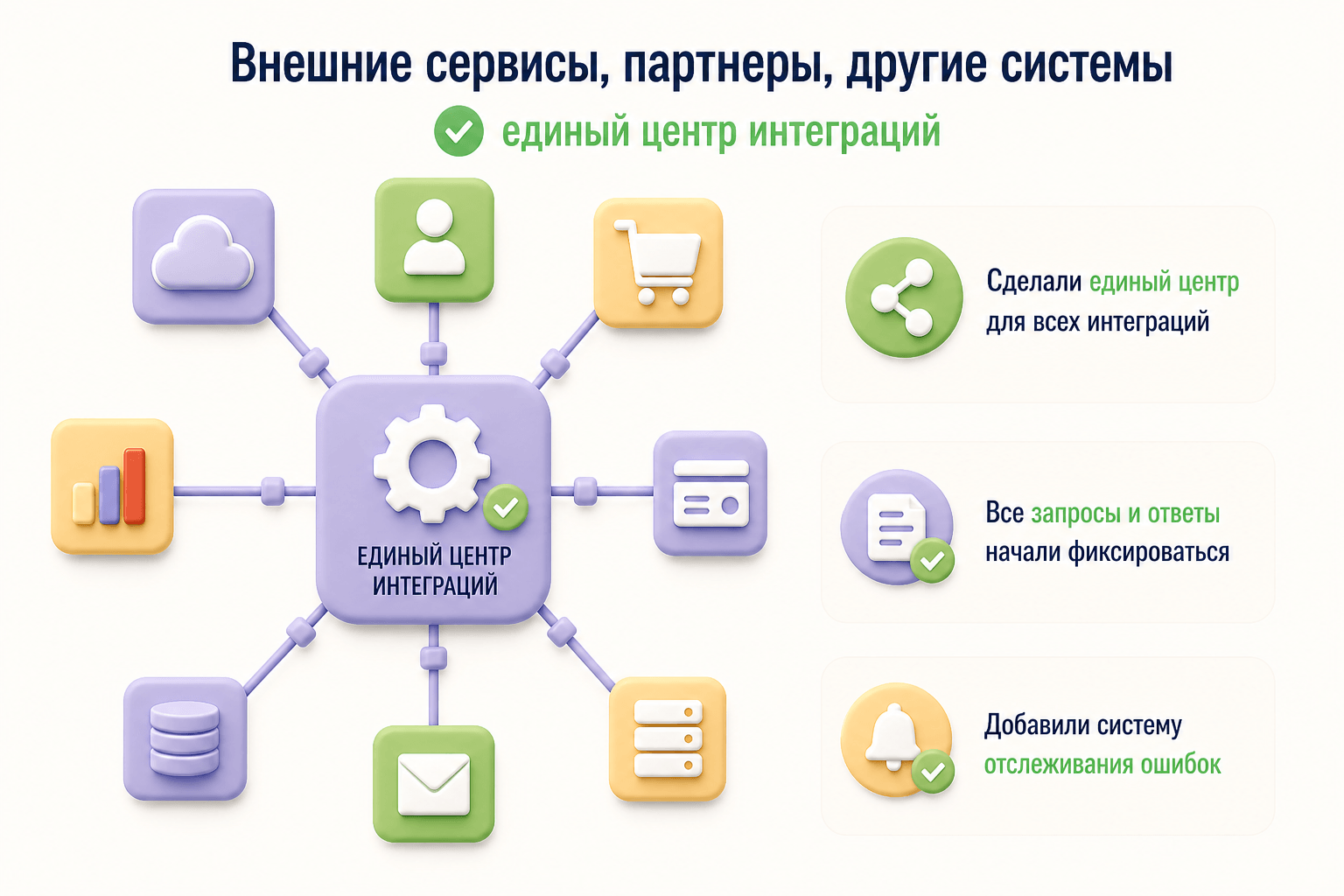
Внедрение шины данных. Для нормализации хаотичной работы с внешними сервисами мы внедрили собственную шину данных на базе Kafka. Теперь любое взаимодействие — отправка данных, запрос статусов, получение ИИ-описаний — проходило через этот контролируемый контур. Шина записывает все сообщения в БД, фиксирует статусы и ошибки, что впервые сделало интеграции прозрачными
Переработка интеграций с внешними системами:
- Ключевая система обмена данными. Полностью переписали формирование файлов для SOAP и REST API. Внедрили предобработку данных: исключение запрещённых символов, валидацию по справочникам сервиса. Настроили полный цикл обмена. Все процессы замкнули на шину данных и тестовые контуры.
- CRM-система. Наладили полный цикл: отправка заявки, отслеживание статуса, получение данных и их валидация. Обработали нестабильность API (сервер мог вернуть 500 ошибку, но данные при этом записать — мы реализовали обработку таких коллизий).
- Внешние шины проектов. Там, где возможно, перевели получение данных с периодического опроса API на чтение очередей Kafka. Это дало гарантию доставки и снизило нагрузку.
Выстраивание процессов разработки:
- Подняли нормальный тестовый контур и «связали» его с тестовыми средами внешних систем.
- Внедрили Sentry и логирование — впервые появилась прозрачность по ошибкам.
- Настроили автоматический деплой и внедрили использование alembic для версионирования миграций БД.
Решили вопрос с отчётностью: после многократных переделок (до 5 раз на один документ) мы изучили все нормативные требования и создали собственные шаблоны, которые утвердили у заказчика. Это сняло проблему «придирок к запятым» раз и навсегда.
Этап3.Развитиеплатформы:отструктурнойстабилизациикинтеллектуальномупоиску
После того как архитектура реестра была stabilizирована, а время загрузки страниц сокращено в десятки раз, мы перешли к следующему этапу — улучшению пользовательского опыта и расширению возможностей самой платформы-агрегатора заказчика.
На основной платформе, где представлены инвестиционные проекты, консалтинговые услуги и компании из сфер драгоценных металлов и недвижимости, требовалось сделать поиск, понимающий сложные профессиональные запросы: от поиска стартапов по технологиям до анализа объектов недвижимости по доходности.
Стандартный поиск не учитывал контекст и выдавал общие результаты. Данные на платформе оказались «шумными»: анкеты заполнялись вручную, содержали дубли, пропуски и разную структуру. Просто подключить нейросеть было нельзя — на «грязных» данных она бы галлюцинировала и выдавала некорректные ответы.

Как мы это сделали:
- Разработали собственный скрапер, который обошёл сайты компаний и автоматически собрал актуальные данные по 98 000 профилей
- Выстроили многоуровневую очистку: удалили дубли через TF-IDF, отфильтровали технический мусор, унифицировали структуру анкет
- Перевели очищенные данные в векторное представление с помощью YandexGPT PRO и сохранили в ChromaDB
- Внедрили интеллектуальный поиск на базе RAG (Retrieval-Augmented Generation), при котором модель ищет ответ не в своей «памяти», а в актуальных данных платформы
Этот опыт стал логичным продолжением нашей работы над реестром. Если на первых двух этапах мы решали задачу «как сделать систему быстрой и стабильной», то здесь — «как сделать данные осмысленными и полезными для пользователя».
Результат: поиск начал понимать инвестиционные запросы и выдавать точные ответы без галлюцинаций. Доля отказов снизилась на 24%, конверсия выросла на 18%. Заказчик получил фундамент для масштабирования — от интеллектуальных рекомендаций до аналитики рынка.
Подробнее об этом — в кейсе: Очистили 98 000 «шумных» профилей и внедрили ИИ-поиск, который понимает инвестиционные запросы.
Чтовитогеполучилось
Заказчик передал нам проект реестра в состоянии, близком к полной остановке: страницы грузились по минуте, отчётность не сдавалась, интеграции не работали, а впереди маячила ключевая отраслевая презентация.
Мы в экстренном режиме стабилизировали систему тактическими решениями, а затем планомерно, за год, переписали архитектурный фундамент. В результате скорость загрузки страниц выросла в десятки раз, а сам продукт не только выжил, но и продолжил активное развитие.
Мы перестроили процессы под строгую приёмку с высокими требованиями к оформлению и впервые сделали внешние интеграции прозрачными и управляемыми через шину данных. Заказчик, дважды обжигавшийся на других командах, увидел качественную работу «как есть» и стал нам доверять.
Дальше мы перешли от стабилизации к развитию: на основной платформе-агрегаторе заказчика внедрили интеллектуальный поиск на базе RAG, который понимает сложные инвестиционные запросы и работает на очищенных нами данных по 98 000 профилей. Это дало снижение доли отказов на 24% и рост конверсии на 18%.
Сегодня и реестр, и основная платформа получили обновлённый UI, мобильную версию и продолжают масштабироваться. А наша команда вынесла уникальный опыт: работа с экстремально сложным legacy, строгими бюрократическими рамками, нестабильными внешними API, а также внедрение ИИ-решений на «грязных» данных. Этот опыт стал школой для всех участников — и в техническом, и в организационном плане.
Технологии
Частозадаваемыевопросы
Кейсы,которымимыгордимся





